Amazon DynamoDB is a fully managed NoSQL document storage engine. In an earlier article on the StratusGrid blog, we discussed how you can use the AWS SDK for Rust to create a DynamoDB table and insert documents into it. Now let’s shift our focus to data retrieval from DynamoDB, known colloquially as querying.
Although retrieving data may sound simple on the outside, DynamoDB provides a complex set of mechanisms that help you find the data you’re looking for. There are two mechanisms for retrieving data from DynamoDB: table scanning and querying. Table scan operations are resource-intensive and require examination of every document. Using the DynamoDB query operation is highly recommended, as it can take advantage of the internal storage structure to optimize data retrieval.
The API parameter that you’ll be using, to query data using partition and sort keys, is called the key condition expression. The key condition expression is a limited, but adequate, language used by developers to specify which partition to query for documents, and which additional criteria to apply to the sort key, if any.
Prerequisites
Before you read the rest of this post, you should start with our previous post that introduces DynamoDB and the AWS SDK for Rust. We will be continuing approximately from where we left off, after learning to create a DynamoDB table and writing documents into the table.
Feel free to adapt the code from the previous article to insert a larger number of items, to practice querying with.
Understanding DynamoDB Query Operations
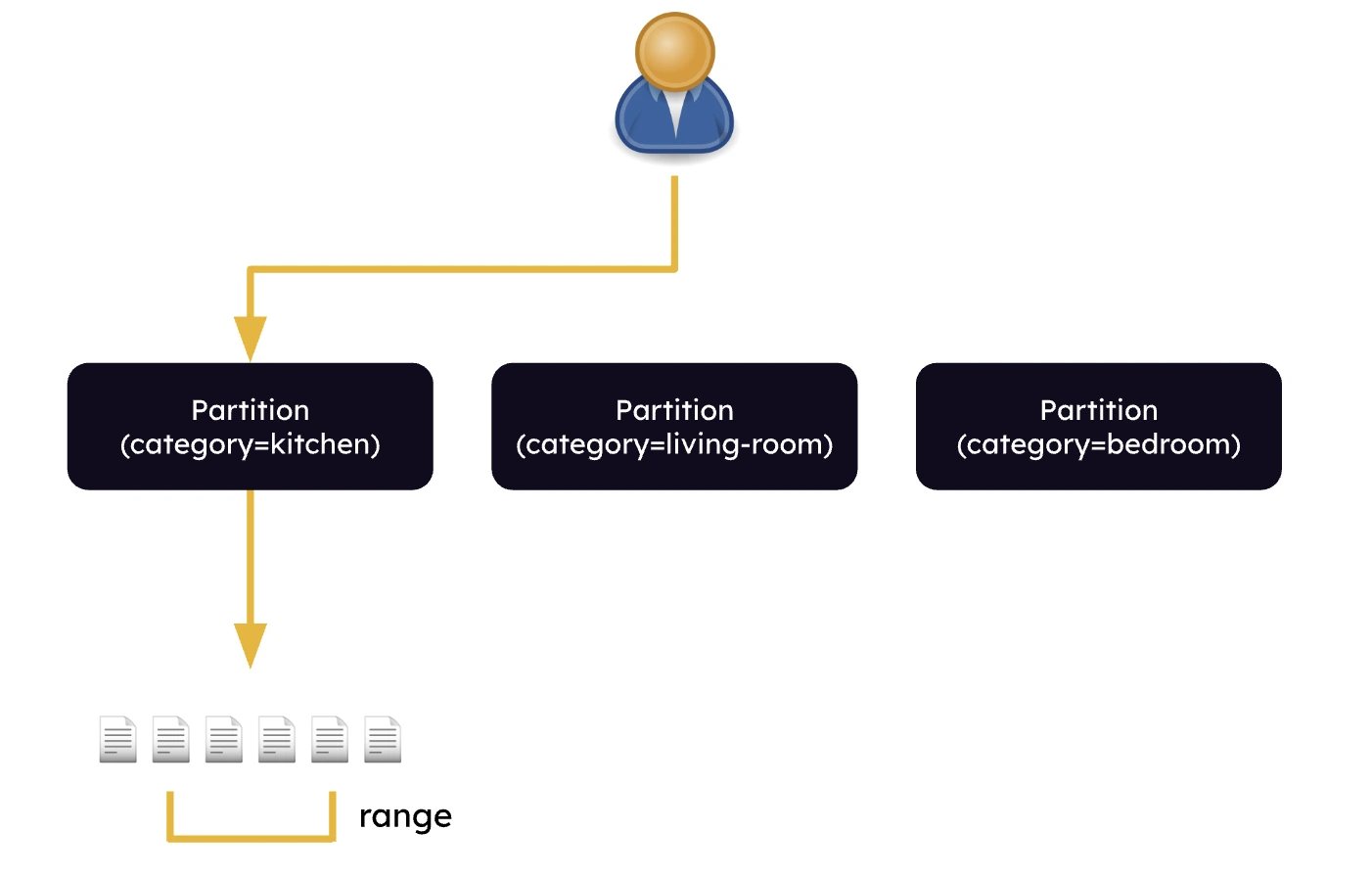
When you issue a query operation against a DynamoDB table, you must specify a partition that you want to retrieve data from. For example, in a product catalog, that is partitioned by product category, you would run a query against a specific, known category. In the figure below, you can see that the developer issues a query against the “kitchen” product category.
If you defined a “sort” (range) key in your DynamoDB table schema, you can optionally specify a key condition, and a filter, to limit the results returned from the partition query. Filters are different key conditions, however. Filters are applied after documents have already been retrieved from the database. It’s best to apply necessary criteria to your key condition first, and then use further filters if required.
Querying DynamoDB in Rust
Let’s shift gears to coding against Amazon DynamoDB in Rust. We’ll be using the DynamoDB client struct to execute various low-level API calls. To run queries, there’s one function that we need to focus on, concisely named query().
If you’re looking at the query() documentation, it might appear overwhelming at first. Start with the basics, and work your way to more advanced use cases. Eventually, everything will make sense. The API parameters that you must specify are:
- The table_name() that you’re querying
- The partition key, using key_condition_expression()
- Partition key value, using expression_attribute_values()
When you create a key condition expression, you create a placeholder to inject values into the expression, rather than hard-coding them. For example, to query a product category, you might have a key condition expression like “category = :input_value”. Then, your partition key value would specify the :input_value placeholder, and inject a string value like “kitchen.” The API can be confusing for beginners, but if you practice with it, it will make sense.
Let’s take a look at a Rust code sample of a basic partition query, and dissect it.
let query_result = ddb_client.query()
.table_name("trevor-products")
.key_condition_expression("category = :inputcategory")
.expression_attribute_values(":inputcategory", AttributeValue::S("kitchen".to_string()))
.send().await;
As you can see, we start by specifying the table name, using the table_name() function. Next, we specify the partition key_condition_expression(), and use a placeholder for the value of the category we want to target. Finally, we specify a substitution for the category value placeholder, by calling the expression_attributes_values() function.
Instead of printing out all the data for now, you can just print out the number of documents that were returned from the query.
if query_result.is_ok() {
println!("Query succeeded. {} items found", query_result.as_ref().unwrap().count);
}
else {
println!("Error occurred during querying");
println!("{:#?}", query_result.err());
}
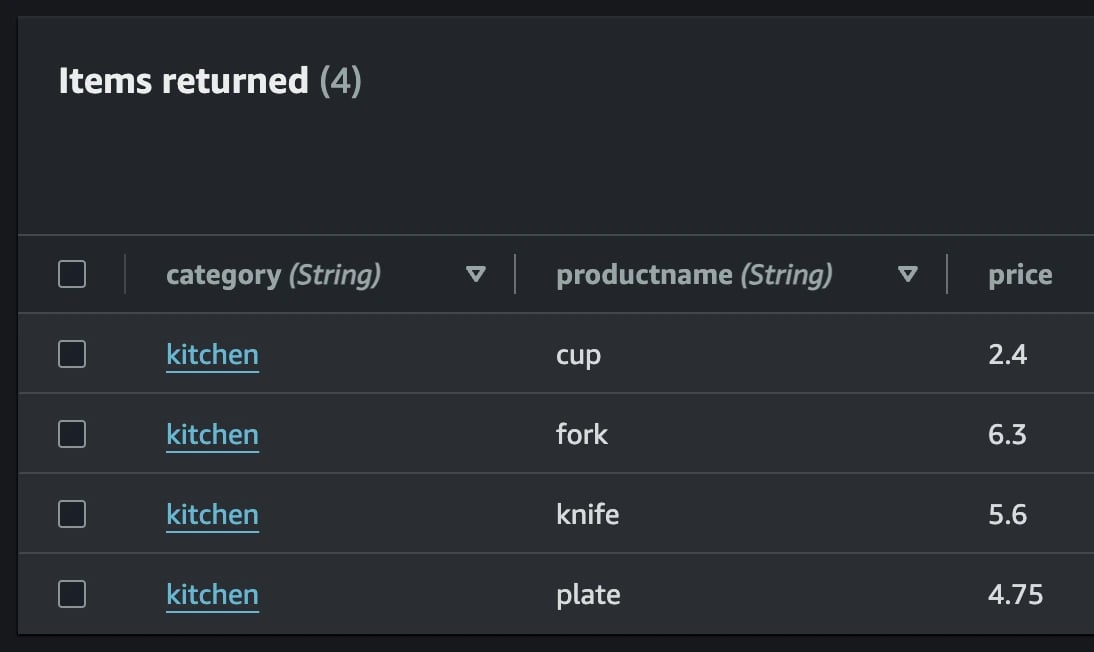
As long as you have documents matching the key condition expression, you should see a positive result. Using the AWS Management Console to view my DynamoDB table, I can see that I should have 4 matching items, based on the category attribute value.
Retrieve DynamoDB Attribute Values
So far, we have retrieved documents from DynamoDB, however we have not yet retrieved the individual attribute values from each document. Let’s take a look at how to accomplish that now.
Remember that DynamoDB supports a variety of data types for attributes, including Number, Binary, String, String Set, and so on. For now, we’ll just focus on String and Number types, which correspond to product category, name, and price.
Using the query results from the previous section, let’s iterate across each document, and find out how to get the attributes and values. Remember that each DynamoDB document can have different attributes that are not part of the partition and sort keys. There’s no guarantee that all documents will have the exact same attributes. Therefore, we need a mechanism to discover the attributes and values dynamically.
In our product data example, all of the documents coincidentally share the same structure. They all have a price attribute in addition to the category & name attributes that belong to the partition and sort keys. Again, there are no requirements that your data structures must all have the same attributes. Some products could include description or discount-price attributes, while others simply don’t specify these. It’s your decision, as a developer, to determine your data structure and ensure your code handles it accordingly.
In the if statement, that checks the query results, remove the println! statement, and replace it with the snippet below.
for document in query_result.unwrap().items.unwrap() {
for attr in document.iter() {
let value = attr.1.as_s()
.or(attr.1.as_n())
.unwrap();
println!("{} = {}", attr.0, value);
}
}
Now, instead of simply printing the number of queried documents, we are actually iterating over the documents and retrieving attributes and values. First, you need to unwrap() the items field of the query results, and then use the iter() function to iterate over each document. As we iterate over each document, the attr variable gets populated with the current item as a Rust tuple type.
The 0th (first) element of the tuple contains a reference to the attribute name (ie. kitchen) as a Rust String type; the 1st (second) element of the tuple contains a reference to the attribute’s value (ie. plate, fork). When you retrieve the attribute value, you must attempt to interpret it as one of the supported DynamoDB data types. If the first attempt to interpret the value fails, you can use the or() function to attempt a different data type. Finally, you must unwrap() the value, as it is contained in the Rust Result<T, E> type. In the example above, you can add more calls to or(); we simply use String and Number data types for this example.
Filtering Query Results from DynamoDB
After your DynamoDB query has retrieved results from the table, you have an additional opportunity to apply filters to the data, before it’s returned to your Rust application. The filter capability is unique as it applies to document attributes other than the partition and sort keys. In fact, you cannot use the partition and sort keys in a filter.
The syntax to create a filter is similar to the query syntax. You specify an attribute name, a comparison operator, and a comparator value. In the DynamoDB query API, this parameter is called the “filter expression.” Just like with the key condition expression, filter expressions allow you to insert placeholders, to inject values into the expression with expression_attribute_values().
Let’s take a look at a complete query example that includes a post-query filter.
let query_result = ddb_client.query()
.table_name("trevor-products")
.key_condition_expression("category = :inputcategory")
.expression_attribute_values(":inputcategory", AttributeValue::S("kitchen".to_string()))
.filter_expression("price BETWEEN :val1 and :val2")
.expression_attribute_values(":val1", AttributeValue::N("0.0".to_string()))
.expression_attribute_values(":val2", AttributeValue::N("4.0".to_string()))
.send().await;
In the snippet above, you can see we’ve added a call to the filter_expression() function, which populates the filter in the request. We’ve also added two more calls to expression_attribute_values(), as we need to compare the price to a lower bound and upper bound. This query retrieves products, in a specific partition (category), and within a certain price range.
There are many other comparison operators and functions you can select from, in your filter expressions. Feel free to experiment with some of the others.
Iterate Over Pages of Query Results
Another feature of the Amazon DynamoDB API is the ability to retrieve pages of query results. This helps your application process data more efficiently, when you’re working with very large datasets. For example, rather than retrieving a list of, 50k documents in one response, you retrieve chunks of the results as individual “pages” of data. After receiving a data page, you can optionally request additional pages depending on how the user interacts with your application. You can also use this technique to scale your applications by delegating data pages to separate threads and taking advantage of multi-processing performance.
In order to paginate results, we need to call the into_paginator() function on the QueryFluentBuilder object. In return, this gives us a QueryPaginator struct. We can set the number of items per page, by using the page_size() function, before finally calling send(). Rather than returning a Rust future, send() will return a PaginationStream struct, which controls iteration over data pages. Because the PaginationStream has internal state to control data page iteration, it must be declared as mutable.
Let’s look at a complete example. We will obtain all documents from the category named “kitchen” and page over them, with 2 items per page.
let mut query_result = ddb_client.query()
.table_name("trevor-products")
.key_condition_expression("category = :inputcategory")
.expression_attribute_values(":inputcategory", AttributeValue::S("kitchen".to_string()))
.into_paginator()
.page_size(2)
.send();
We need to instruct the paginator to retrieve the next page of documents, using the try_next() function, and then await that future. Typically this would be done in a looping construct until all data pages have been processed.
loop {
let next_page = query_result.try_next().await;
if let Ok(Some(page)) = next_page {
println!("Getting next page ...");
for doc in page.items() {
println!("name: {}", doc.get("name").unwrap().as_s().unwrap());
}
}
else {
break;
}
}
In the above code, we create an infinite loop until all data pages have been exhausted, at which point we use the Rust break keyword to exit the loop. To obtain another data page, we call try_next() and await the async future. Next, we use the if..let Rust statement to assign the results to a variable named page, by unwrapping the Result and Option from the next_page variable. Finally, we can iterate through each document by using a for loop over the items() method on the QueryOutput struct.
You can add more logic to handle a specific number of data pages, change the page size, skip items based on attribute values, and other customizations. This example just shows a basic example of iterating over all documents returned from a DynamoDB partition query.
Obtain Specific Attributes from DynamoDB Documents
In some cases, you may not need to retrieve an entire document from DynamoDB. Imagine that your documents generally have a large number of attributes, perhaps in the vicinity of 100. During a query operation, you can specify which data attributes you wish to retrieve from DynamoDB documents. This feature is known as Projection Expressions. If the fancy name sounds intimidating, just think of it as “included attributes” instead; it’s really simple.
All you need to do is call the projection_expression() function on your QueryFluentBuilder, before sending the request. Simply specify a comma-separated string of the document attributes that you want to include in the DynamoDB query.
let query_result = ddb_client.query()
.table_name("trevor-products")
.key_condition_expression("category = :inputcategory")
.expression_attribute_values(":inputcategory", AttributeValue::S("kitchen".to_string()))
.projection_expression("productname, category")
.send().await;
For attributes with a non-scalar value (ie. StringSet, List, Map), you can specify the child values that you want to retrieve from the attribute. In the case of a List, you can specify an index number in square brackets, after the attribute name, for the value you want to retrieve. If your attribute contains a Map type (key-value pairs), simply specify a period, and the child key that you want to retrieve from the Map. Check out the documentation for examples of working with List and Map attributes.
Beyond the Basics: DynamoDB and Rust
In this article, we have reviewed some of the querying features available in Amazon DynamoDB. Although DynamoDB is a relatively simple key-value storage service on the outside, there are many advanced features available, to satisfy your application’s needs.
Some other topics surrounding DynamoDB, that you may want to explore after reading this article, include the list below.
Optimize, Modernize, and Stabilize with StratusGrid
If you’re ready to take your cloud infrastructure to the next level, StratusGrid, your trusted AWS Consulting Partner, is here to guide you through every step of your AWS cloud journey. From migration and modernization to stabilization and cost optimization, our team of AWS-certified experts is dedicated to transforming your ideas into reality and driving unparalleled growth for your business.
Don't miss out on the opportunity to optimize your cloud usage with tailored software solutions. Book your free consultation now and start maximizing your AWS cloud performance today. Contact us for a consultation now!
BONUS: Find Out if Your Organization is Ready for The Cloud ⤵️