Taming The Storm
Recently I was troubleshooting a service running on Amazon API Gateway and Lambda. The Lambda was connected to a VPC and used a proxy for outbound internet access. End-to-end tests were failing due to the service returning 504 status codes.
As I began troubleshooting the issue, I realized that there are some universal steps that I return to in order to break down complex issues.
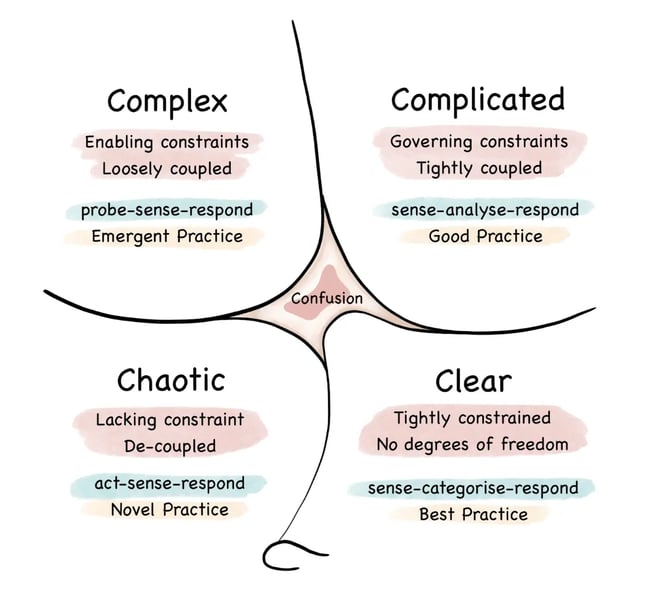
Image Source: Tom@thomasbcox.com - Own work - a re-drawing of the prior artwork found here (https://commons.wikimedia.org/wiki/File:Cynefin_as_of_1st_June_2014.png)
I recently learned about the Cynefin framework and I've found it indispensable in my daily work managing cloud infrastructure. The framework breaks down every situation into four categories: complex, complicated, chaotic, or clear.
I've found that the framework reduces stress, because once you understand the type of your situation, the steps for managing the situation are clearly defined.
The following troubleshooting steps provide similar comfort. No matter the complexity of the situation, you can follow these steps to gather information and move closer to the solution of whatever technical challenge you are facing.
Step 1: Reduce The Scope
Imagine that end-to-end tests for a service are failing during a CodePipeline stage. Tests pass fine in the sandbox environment but fail in the integration environment. T
he first step is to produce the smallest repeatable error. CodePipeline may be sending a request to API Gateway that is proxied to a Lambda integration.
Determine if the error occurs when executing the Lambda directly. If it does, identify the particular function within the Lambda function that is failing. Deploy a new Lambda function in the same environment that contains only the function you identified as failing. Continue to narrow the scope by removing side-effects and unused dependencies.
The point of this stage is to gradually strip away extraneous infrastructure and code dependencies until you have the smallest repeatable error.
Step 2: Reproduce With Different Configurations
Now that you have reduced the scope to the smallest failing test case, try multiple configurations. For example, you may try deploying the same test Lambda into a different environment, or changing the version of a dependency, or testing the Lambda in both VPC and non-VPC configurations.
At this stage, it is important to change just one independent variable at a time, to examine the return status and review debug-level logs.
Step 3: Go Wide And Deep
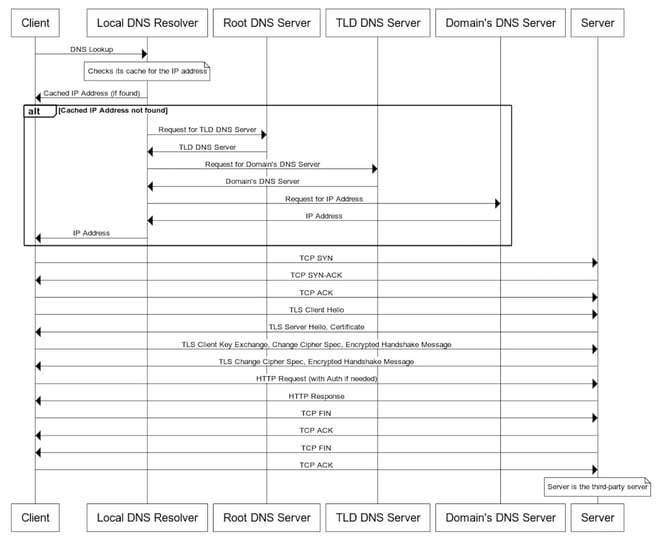
Code running in AWS often interfaces with other services. Now is the time to "go wide and deep" by considering all of the layers and processes that take place in your minimal failing example.
For example, code often reaches out to another service. Within a simple request to a third party, various processes are taking place such as calls to tracing endpoints, the HTTP request and response, TCP connections, TLS negotiation, and auth flows.
Within the code it is important to consider memory management and call stacks to dependent libraries. Begin testing each of these independently.
For example, you can use the Python socket interface to test TCP connectivity to your 3rd party endpoints, or the urllib module to simulate an https request through a reverse proxy. For app profiling, use built-in tools such as process.memoryUsage() and heap profilers.
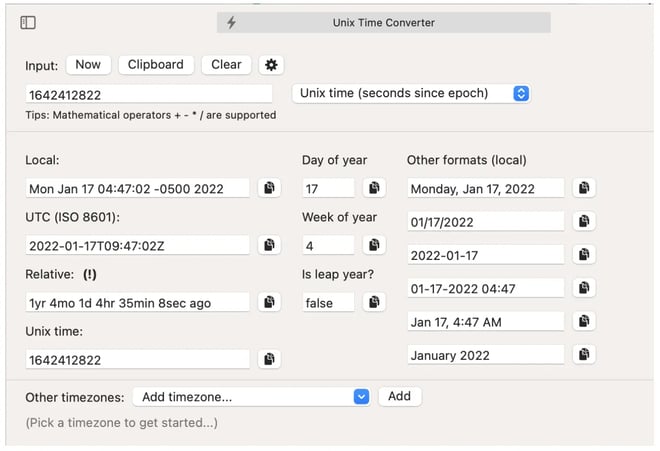
Step 4: Track Timestamps
Determine the time that the error first occurred. Check closed Pull Requests, builds, and infrastructure changes that happened around the same time. Check your AWS Health Dashboard for changes regarding managed services. Correlate CloudWatch Metrics with CloudWatch Logs for your service and for downstream dependencies.
DevUtils is a helpful tool for coordinating timestamps between different sources.
Step 5: Document The Root Cause And Resolution
Hopefully the above steps led you towards a solution to the problem. However, avoid the tendency to switch focus as soon as the solution is found. More troubleshooting is often needed to understand why the solution worked.
Do new tests need to be written? Did the code intercept the exception and generate helpful error messages? Was a breaking change introduced in a third party that broke semantic versioning?
Spend some time understanding the root cause(s) of the issue, build up your defenses to prevent it from happening again, and document both the cause and the solution to the issue.
Embrace The Journey
In the world of live distributed systems, complex issues can be challenging due to the interplay between software, infrastructure, and data. However, following a structured approach can help navigate these issues with confidence and, importantly, reduce stress.
While troubleshooting, be mindful of stress and energy levels. Breakthrough ideas often come while taking a break away from the keyboard.
Remember, it is not only about resolving the issue at hand, but understanding the causes, reinforcing your defenses, and continually improving the resilience of both software and organizational systems.
Embracing this challenge with the right mindset is key to a successful voyage through choppy seas.
BONUS: Find Out if Your Organization is Ready for The Cloud ⤵️