Modernization
Athena Alb Table Terraform Module
Unlock powerful data querying capabilities with StratusGrid's Athena ALB Table Terraform Module. Transform AWS ALB logs into actionable insights...
This article provides a detailed walkthrough, from understanding AWS access logs to efficiently parsing and analyzing them using Athena’s SQL syntax.

A few months ago, I was working on an incident and suddenly the entire fate of the team’s evening depended upon my ability to locate a handful of requests that occurred around a specific point in time. The first thought that came to mind was to check the access logs, and I knew if I was going to be parsing terabytes of access logs then I was going to be using Amazon Athena .
Athena is a Greek goddess associated with wisdom. When your job includes high-pressure situations, it is wise to plan for them ahead of time. This article will help prepare you for those situations when you need Athena to locate a particular piece of information from AWS Access Logs.
Many AWS services generate access logs — S3, CloudFront, and Application Load Balancers (ALBs) to name a few. Although these services generate access logs, the schema for the logs is different for each service. The logs are written to S3 and they provide useful information for troubleshooting.
Busy applications that receive thousands of requests per second can generate terabytes of log data per day, and finding the data you need quickly surpasses the capabilities of old stand-bys like awk and sed.
This is where Amazon Athena comes in. Athena allows you to query massive amounts of data using standard SQL syntax. It is worthwhile to get some practice using Athena before you need it, because the moments you need it are likely to be high-pressure situations. This blog post will walk you through a demonstration of using Athena to parse access log data and provide some reference material should you find yourself in a situation similar to the recent incident I was involved in.

For this article, I created an ALB and pointed it to a server with a default Nginx configuration. I opened the ALB security group to my IP address and made requests using k6:
Before using Athena to query the access logs, we need to create a table from the access logs stored in S3. The syntax for creating a table can be complex. You need to use a SerDe (Serializer/Deserializer). The SerDe defines the table schema, and there are multiple types to choose from.
To sidestep these complexities, there are many CREATE TABLE examples already provided by AWS. I recommend bookmarking these ahead of time. Here are a few that are likely to be helpful:
Each of these URLs contains the CREATE TABLE example. Here is the example we will work from for ALB access logs:
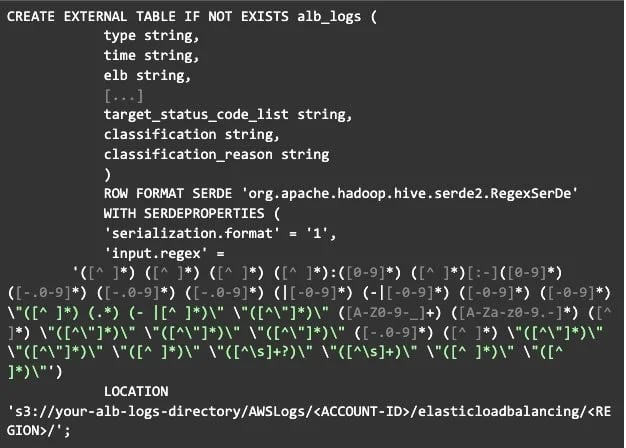
You can see we are using a complex regex to parse log data into named fields like "type, time, client_ip", and so on. It would be a lot of work to create this manually, so keep the above bookmarks handy!
Before running your query, you will need to specify a query result location:
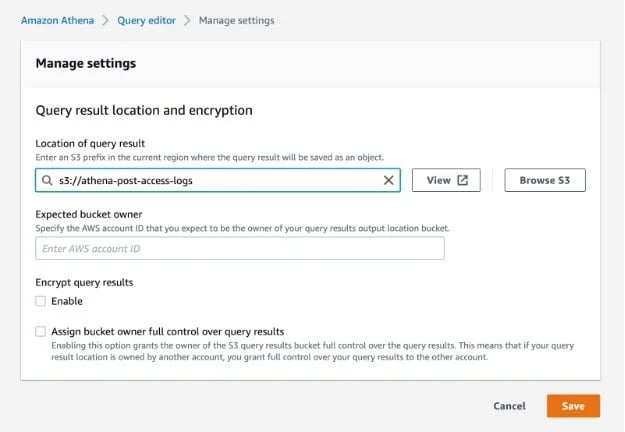
After specifying the query result location, run the query to create your table and you will see a new table in the list of tables. You can click the menu and preview the table. After this, you will see that your log data is nicely parsed into records and fields, and you can query them using SQL syntax:
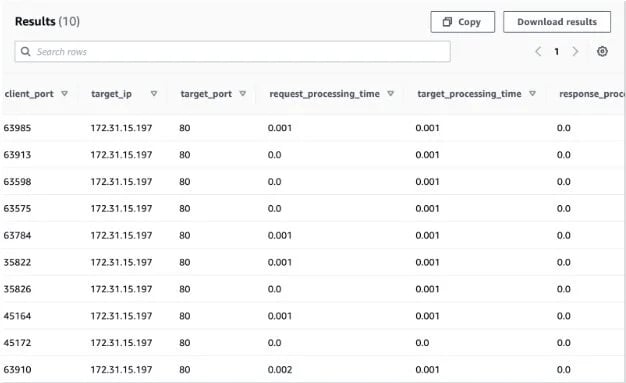
Suppose we want to find all the requests that did not return 200 responses:

Then group those results by IP to find our top offenders:

We can also use regex to locate requests made to a particular URL:

In our CREATE TABLE example, we loaded all the ALB access logs. However, if you have petabytes of data, the Athena queries will timeout. Therefore, it is important to understand how to partition large datasets before you enter a trial by fire.
AWS Athena has a feature called Partition Projection, which will automatically create partitions as new data is added. Since the ALB Access Logs are keyed by day, we can use this for our partition projection. Here is the virtual directory structure of our ALB access log data:
![]()
Here is the CREATE TABLE example provided by AWS that includes Partition Projections by day:
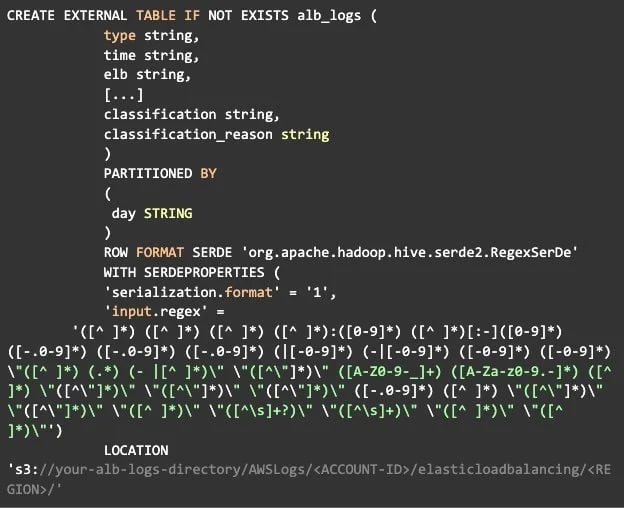
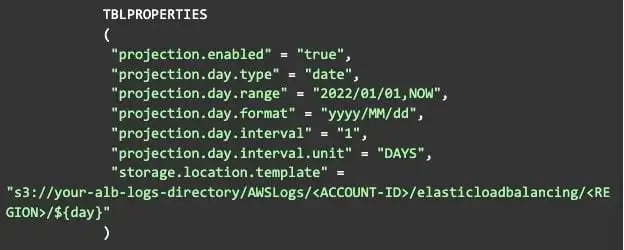
***NOTE: As of April 20th, 2022 there is a typo in the AWS documentation for the CREATE TABLE syntax with a partition. There should not be a semicolon at the end of the LOCATION line.
Notice how we are now partitioning by day, and we have enabled projection and provided information to the projection function on how to generate new projections. Lastly, we include the `${day}` variable in the storage location template. It is not necessary to understand these details unless you are working with a log format for which example table creations do not exist.
Now that we are partitioning the data, when you include a "day" in your WHERE clause in the format of YYYY/MM/DD, you will be querying a reduced set of data and the query will be much faster (and cheaper)!
![]()
I hope this article has helped you become a little more knowledgeable about the value of Amazon Athena. The preparation you put in now will help tremendously when these skills are needed during stressful situations. For more tips and advice related to the Cloud and DevOps, please follow me on X @pentekostos.
We are StratusGrid, an AWS Certified Partner, and we can help you elevate your Amazon Athena capabilities to new heights. Whether you're navigating through complex datasets or seeking to enhance your Cloud and DevOps skills, we're here to empower your success.
Contact us today and take the first step towards unlocking new possibilities with Amazon Athena.
BONUS: Download Your FinOps Guide to Effective Cloud Cost Optimization Here ⤵️
.webp?width=1307&height=448&name=FinOps-Guide-Downloadable%20(2).webp)
Unlock powerful data querying capabilities with StratusGrid's Athena ALB Table Terraform Module. Transform AWS ALB logs into actionable insights...
Learn how to scan AWS DynamoDB tables using the AWS SDK for Rust. Learn how to set up your Rust project, execute it, & paginate scan operations.
Microsoft is under federal investigation for its lax cybersecurity protocols. StratusGrid goes through the events and presents our take.